Scala Floor A Spark Column

Trim Lighting Floors Love The Stain And White Combination Like The Column With The Staircase Stairs Design Interior House Staircase Design

Boston Property Log In Home Classic Interior Interior

Dataframe With Dynamic When Condition Using With Column Stack Overflow

2019 Codaawards Highlight The Best Site Specific Artwork Hotel Lobby Design Lobby Design Lobby Interior Design

Gallery Of Ih Residence Andramatin 10 Dutch Colonial Homes Corridor Design Tropical Architecture

Painted Column Ideas Column And The Ceiling Panels Were Painted In Different Shade Minimalist Interior Design Interior Design School Minimalist Interior

So let s get started.
Scala floor a spark column.

Reality And Misconceptions About Big Data Analytics Data Lakes And The Future Of Ai In 2020 Big Data Big Data Analytics Business Intelligence

Ancient Live Edge Dining Table Live Edge Dining Table Live Edge Table Live Edge Design

Replace Roman Columns With Base Cabinets And Craftsman Style Beams House House Design Home
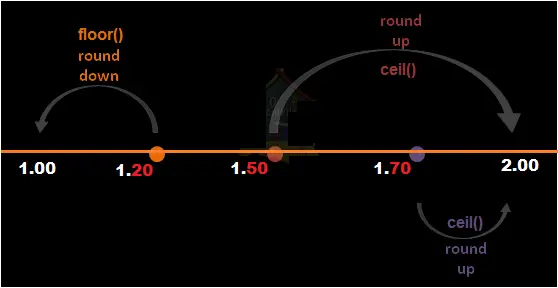
Round Up Round Down And Round Off In Pyspark Ceil Floor Pyspark Datascience Made Simple

Spark 28135 Better Double Support In Sql Ceil Floor Functions Issue 24940 Apache Spark Github

Archway Columns Home Hardwood Floors Looking Into Kitchen Archways In Homes House Design Interior Columns

Christie Digital Microtiles Integrated Into A Dirtt Wall 33 Microtiles Wall Design Wall Graphics Wall

Square Wood Columns Interior Home Who We Are Remodeling Handyman Services Custom Woodworking Energy Moldings And Trim Interior Columns Home

Beautiful Chicago Loft Inside A Century Old Industrial Building Loft Design Interior Architecture Loft Apartment

Contemporary Sgnw Custom Home By Metropole Architects House Design Dream House Contemporary House Design

What Is Slab Beam Column And Footing Construction Building Columns Beams Column

Pin On Technology

Hadoop And Big Data Enterprise Challenges Big Data Data Public Cloud

Things I Wish I D Known About Spark When I Started One Year Later Edition Business Data And Intelligence Enigma

Podium For Floor With Double Column Design Mdf And Aluminum Black Lectern Lecterns Column Design

Hadoop Ecosystem Including Hive H Base Pig Sqoop And Zookeeper Hadoop Is An Open Source Software Framework Used In 2020 Big Data Distributed Computing Data Science

White Polished Venetian Plaster At Columns Polished Marble Floors And Bar Counters And Darkened Granite For Polish Marble Floor Marble Floor Venetian Plaster

Pin By Florence Voo On Screen Foyer Design Room Partition Designs Living Room Partition
Https Encrypted Tbn0 Gstatic Com Images Q Tbn 3aand9gcq Uvwixcwouqmnptim3jvhohlmymwebqjulepd40s33wwfwtg Usqp Cau

Box Newel Post Recessed Panel Mission Style 5 Hickory Stair Railing Design Stair Newel Post Stairway Design

Charismatic Spark Gold Sequin Maxi Dress Sequin Formal Dress Dresses Formal Dresses

A Message From The Dean Covid 19 Update The Cooper Union

Restaurants In Santa Fe Loretto Chapel Staircase Design Loretto

Kitchen Dining Area Design Dining Area Design Ground Floor Plan Concrete Column
Source : pinterest.com
